Listening and Speaking with the Computer
Opportunities for learners to work interactively with the computer on listening and speaking have developed exponentially over the past decade, especially with advances in Artificial Intelligence (AI). There are applications these days that can listen to one’s speech and respond relatively correctly. For instance, asking Amazon’s Alexa or Google Home, “What day is today?” is most likely replied to with a grammatically, semantically, and contextually correct response. However, these intelligent personal assistants (IPAs) are still in development and, although they function so fascinatingly in our lives, they are limited by how they are made and what contents are programmed in. Nevertheless, IPAs can be great tools to practice speaking and listening. In a case study on four Japanese EFL learners’ perception of Amazon’s Alexa, Dizon (2017) found that the IPA was only accurate 50% of the time, understanding 18 of 36 commands given by students. Also, the results showed that students’ unintelligible pronunciation accounted for 28% of Alexa’s miscomprehension, which made them try to “modify their output in order to be understood by Alexa” (p. 820). Therefore, these emerging technologies offer potential for use in the language classroom.
Moreover, there are speech recognition tools in most popular commercial English learning software such as Rosetta Stone (https://www.rosettastone.com/), Rocket Languages, (https://www.rocketlanguages.com/), and Mango Languages (https://mangolanguages.com/) that allow learners to compare the comprehensibility of their utterances to that of native speakers. These programs can model native speaker pronunciation aurally that learners listen to, repeat, and receive feedback to from the computer. For example, English Language Speech Assistant (ELSA) (https://www.elsaspeak.com/) is a cross-platform (iOS and Android) interactive smartphone application that can provide tailor-made training on pronunciation based on students’ first language.
Figure 3.3 presents an example from ELSA’s job interview exercises. Here, the learner’s pronunciation has been compared to that of a typical native English speaker and color-coded (red, yellow, and green) based on their similarity, with green and red representing the two sides of the intelligibility and unintelligibility continuum, respectively.
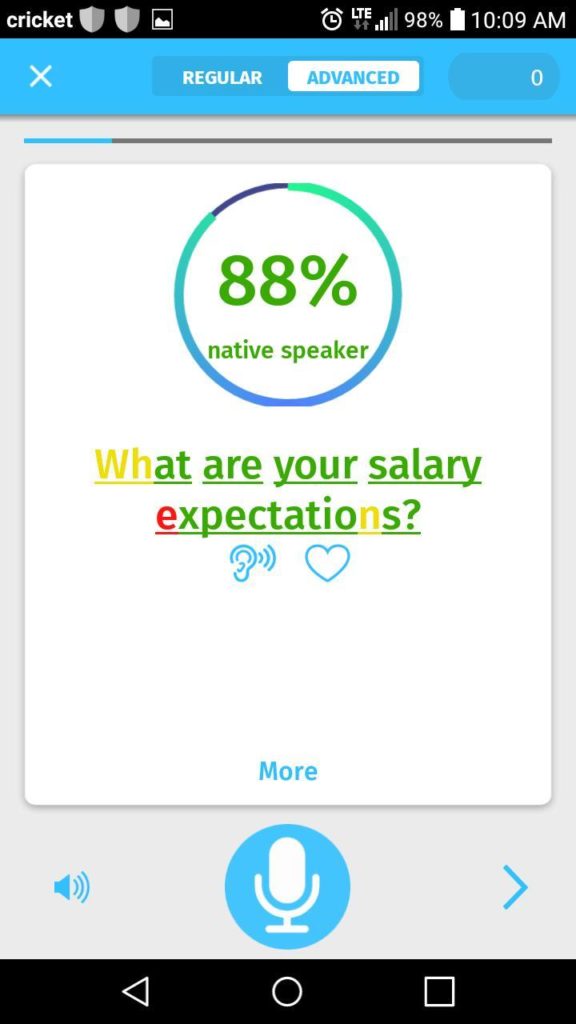
Figure 3.3 An example from ELSA’s job interview exercises.
Dictation software packages such as Windows Speech Recognition (built-in in all Windows machines), Apple Dictation (built-in all Mac and iOS machines), and Google Docs Voice Typing (http://docs.google.com) allow users, once they have trained the software, to speak into a microphone and watch the software type their speech onto a page. Watching the software interpret the learner’s speech provides feedback in the mistakes that it reveals in pronunciation and grammar. The user can then instruct the computer orally how to manage the mistakes that it has found.
As electronic technologies become more advanced, students will be able to work around, through, and with the computer. For now, however, using the computer as a partner is still in development, but computer as a tool provides learners with numerous opportunities to improve their target language listening and speaking skills.

Feedback/Errata