38 Measures of Intelligence
[latexpage]
Learning Objectives
By the end of this section, you will be able to:
- Explain how intelligence tests are developed
- Describe the history of the use of IQ tests
- Describe the purposes and benefits of intelligence testing
While you’re likely familiar with the term “IQ” and associate it with the idea of intelligence, what does IQ really mean? IQ stands for intelligence quotient and describes a score earned on a test designed to measure intelligence. You’ve already learned that there are many ways psychologists describe intelligence (or more aptly, intelligences). Similarly, IQ tests—the tools designed to measure intelligence—have been the subject of debate throughout their development and use.
When might an IQ test be used? What do we learn from the results, and how might people use this information? IQ tests are expensive to administer and must be given by a licensed psychologist. Intelligence testing has been considered both a bane and a boon for education and social policy. In this section, we will explore what intelligence tests measure, how they are scored, and how they were developed.
MEASURING INTELLIGENCE
It seems that the human understanding of intelligence is somewhat limited when we focus on traditional or academic-type intelligence. How then, can intelligence be measured? And when we measure intelligence, how do we ensure that we capture what we’re really trying to measure (in other words, that IQ tests function as valid measures of intelligence)? In the following paragraphs, we will explore the how intelligence tests were developed and the history of their use.
The IQ test has been synonymous with intelligence for over a century. In the late 1800s, Sir Francis Galton developed the first broad test of intelligence (Flanagan & Kaufman, 2004). Although he was not a psychologist, his contributions to the concepts of intelligence testing are still felt today (Gordon, 1995). Reliable intelligence testing (you may recall from earlier chapters that reliability refers to a test’s ability to produce consistent results) began in earnest during the early 1900s with a researcher named Alfred Binet ([link]). Binet was asked by the French government to develop an intelligence test to use on children to determine which ones might have difficulty in school; it included many verbally based tasks. American researchers soon realized the value of such testing. Louis Terman, a Stanford professor, modified Binet’s work by standardizing the administration of the test and tested thousands of different-aged children to establish an average score for each age. As a result, the test was normed and standardized, which means that the test was administered consistently to a large enough representative sample of the population that the range of scores resulted in a bell curve (bell curves will be discussed later). Standardization means that the manner of administration, scoring, and interpretation of results is consistent. Norming involves giving a test to a large population so data can be collected comparing groups, such as age groups. The resulting data provide norms, or referential scores, by which to interpret future scores. Norms are not expectations of what a given group should know but a demonstration of what that group does know. Norming and standardizing the test ensures that new scores are reliable. This new version of the test was called the Stanford-Binet Intelligence Scale (Terman, 1916). Remarkably, an updated version of this test is still widely used today.
In 1939, David Wechsler, a psychologist who spent part of his career working with World War I veterans, developed a new IQ test in the United States. Wechsler combined several subtests from other intelligence tests used between 1880 and World War I. These subtests tapped into a variety of verbal and nonverbal skills, because Wechsler believed that intelligence encompassed “the global capacity of a person to act purposefully, to think rationally, and to deal effectively with his environment” (Wechsler, 1958, p. 7). He named the test the Wechsler-Bellevue Intelligence Scale (Wechsler, 1981). This combination of subtests became one of the most extensively used intelligence tests in the history of psychology. Although its name was later changed to the Wechsler Adult Intelligence Scale (WAIS) and has been revised several times, the aims of the test remain virtually unchanged since its inception (Boake, 2002). Today, there are three intelligence tests credited to Wechsler, the Wechsler Adult Intelligence Scale-fourth edition (WAIS-IV), the Wechsler Intelligence Scale for Children (WISC-V), and the Wechsler Preschool and Primary Scale of Intelligence—IV (WPPSI-IV) (Wechsler, 2012). These tests are used widely in schools and communities throughout the United States, and they are periodically normed and standardized as a means of recalibration. Interestingly, the periodic recalibrations have led to an interesting observation known as the Flynn effect. Named after James Flynn, who was among the first to describe this trend, the Flynn effect refers to the observation that each generation has a significantly higher IQ than the last. Flynn himself argues, however, that increased IQ scores do not necessarily mean that younger generations are more intelligent per se (Flynn, Shaughnessy, & Fulgham, 2012). As a part of the recalibration process, the WISC-V was given to thousands of children across the country, and children taking the test today are compared with their same-age peers ([link]).
The WISC-V is composed of 14 subtests, which comprise five indices, which then render an IQ score. The five indices are Verbal Comprehension, Visual Spatial, Fluid Reasoning, Working Memory, and Processing Speed. When the test is complete, individuals receive a score for each of the five indices and a Full Scale IQ score. The method of scoring reflects the understanding that intelligence is comprised of multiple abilities in several cognitive realms and focuses on the mental processes that the child used to arrive at his or her answers to each test item.
Ultimately, we are still left with the question of how valid intelligence tests are. Certainly, the most modern versions of these tests tap into more than verbal competencies, yet the specific skills that should be assessed in IQ testing, the degree to which any test can truly measure an individual’s intelligence, and the use of the results of IQ tests are still issues of debate (Gresham & Witt, 1997; Flynn, Shaughnessy, & Fulgham, 2012; Richardson, 2002; Schlinger, 2003).
The case of Atkins v. Virginia was a landmark case in the United States Supreme Court. On August 16, 1996, two men, Daryl Atkins and William Jones, robbed, kidnapped, and then shot and killed Eric Nesbitt, a local airman from the U.S. Air Force. A clinical psychologist evaluated Atkins and testified at the trial that Atkins had an IQ of 59. The mean IQ score is 100. The psychologist concluded that Atkins was mildly mentally retarded.
The jury found Atkins guilty, and he was sentenced to death. Atkins and his attorneys appealed to the Supreme Court. In June 2002, the Supreme Court reversed a previous decision and ruled that executions of mentally retarded criminals are ‘cruel and unusual punishments’ prohibited by the Eighth Amendment. The court wrote in their decision:
Clinical definitions of mental retardation require not only subaverage intellectual functioning, but also significant limitations in adaptive skills. Mentally retarded persons frequently know the difference between right and wrong and are competent to stand trial. Because of their impairments, however, by definition they have diminished capacities to understand and process information, to communicate, to abstract from mistakes and learn from experience, to engage in logical reasoning, to control impulses, and to understand others’ reactions. Their deficiencies do not warrant an exemption from criminal sanctions, but diminish their personal culpability (Atkins v. Virginia, 2002, par. 5).
The court also decided that there was a state legislature consensus against the execution of the mentally retarded and that this consensus should stand for all of the states. The Supreme Court ruling left it up to the states to determine their own definitions of mental retardation and intellectual disability. The definitions vary among states as to who can be executed. In the Atkins case, a jury decided that because he had many contacts with his lawyers and thus was provided with intellectual stimulation, his IQ had reportedly increased, and he was now smart enough to be executed. He was given an execution date and then received a stay of execution after it was revealed that lawyers for co-defendant, William Jones, coached Jones to “produce a testimony against Mr. Atkins that did match the evidence” (Liptak, 2008). After the revelation of this misconduct, Atkins was re-sentenced to life imprisonment.
Atkins v. Virginia (2002) highlights several issues regarding society’s beliefs around intelligence. In the Atkins case, the Supreme Court decided that intellectual disability does affect decision making and therefore should affect the nature of the punishment such criminals receive. Where, however, should the lines of intellectual disability be drawn? In May 2014, the Supreme Court ruled in a related case (Hall v. Florida) that IQ scores cannot be used as a final determination of a prisoner’s eligibility for the death penalty (Roberts, 2014).
THE BELL CURVE
The results of intelligence tests follow the bell curve, a graph in the general shape of a bell. When the bell curve is used in psychological testing, the graph demonstrates a normal distribution of a trait, in this case, intelligence, in the human population. Many human traits naturally follow the bell curve. For example, if you lined up all your female schoolmates according to height, it is likely that a large cluster of them would be the average height for an American woman: 5’4”–5’6”. This cluster would fall in the center of the bell curve, representing the average height for American women ([link]). There would be fewer women who stand closer to 4’11”. The same would be true for women of above-average height: those who stand closer to 5’11”. The trick to finding a bell curve in nature is to use a large sample size. Without a large sample size, it is less likely that the bell curve will represent the wider population. A representative sample is a subset of the population that accurately represents the general population. If, for example, you measured the height of the women in your classroom only, you might not actually have a representative sample. Perhaps the women’s basketball team wanted to take this course together, and they are all in your class. Because basketball players tend to be taller than average, the women in your class may not be a good representative sample of the population of American women. But if your sample included all the women at your school, it is likely that their heights would form a natural bell curve.
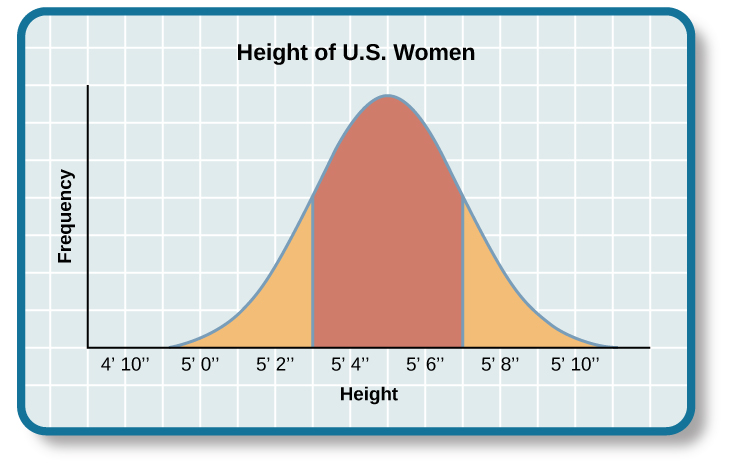
The same principles apply to intelligence tests scores. Individuals earn a score called an intelligence quotient (IQ). Over the years, different types of IQ tests have evolved, but the way scores are interpreted remains the same. The average IQ score on an IQ test is 100. Standard deviations describe how data are dispersed in a population and give context to large data sets. The bell curve uses the standard deviation to show how all scores are dispersed from the average score ([link]). In modern IQ testing, one standard deviation is 15 points. So a score of 85 would be described as “one standard deviation below the mean.” How would you describe a score of 115 and a score of 70? Any IQ score that falls within one standard deviation above and below the mean (between 85 and 115) is considered average, and 68% of the population has IQ scores in this range. An IQ score of 130 or above is considered a superior level.
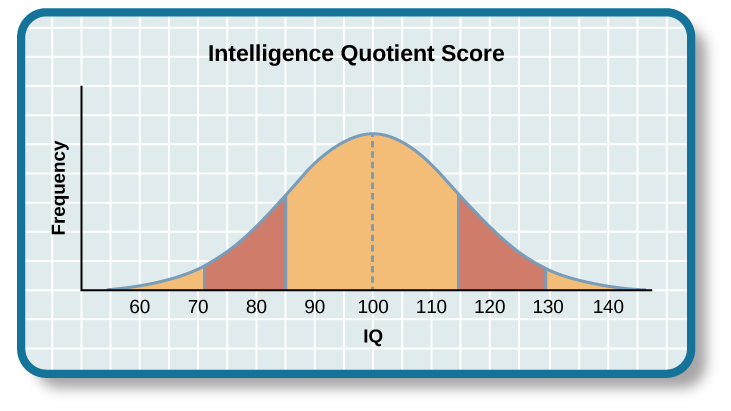
Only 2.2% of the population has an IQ score below 70 (American Psychological Association [APA], 2013). A score of 70 or below indicates significant cognitive delays, major deficits in adaptive functioning, and difficulty meeting “community standards of personal independence and social responsibility” when compared to same-aged peers (APA, 2013, p. 37). An individual in this IQ range would be considered to have an intellectual disability and exhibit deficits in intellectual functioning and adaptive behavior (American Association on Intellectual and Developmental Disabilities, 2013). Formerly known as mental retardation, the accepted term now is intellectual disability, and it has four subtypes: mild, moderate, severe, and profound ([link]). The Diagnostic and Statistical Manual of Psychological Disorders lists criteria for each subgroup (APA, 2013).
| Intellectual Disability Subtype | Percentage of Intellectually Disabled Population | Description |
|---|---|---|
| Mild | 85% | 3rd- to 6th-grade skill level in reading, writing, and math; may be employed and live independently |
| Moderate | 10% | Basic reading and writing skills; functional self-care skills; requires some oversight |
| Severe | 5% | Functional self-care skills; requires oversight of daily environment and activities |
| Profound | <1% | May be able to communicate verbally or nonverbally; requires intensive oversight |
On the other end of the intelligence spectrum are those individuals whose IQs fall into the highest ranges. Consistent with the bell curve, about 2% of the population falls into this category. People are considered gifted if they have an IQ score of 130 or higher, or superior intelligence in a particular area. Long ago, popular belief suggested that people of high intelligence were maladjusted. This idea was disproven through a groundbreaking study of gifted children. In 1921, Lewis Terman began a longitudinal study of over 1500 children with IQs over 135 (Terman, 1925). His findings showed that these children became well-educated, successful adults who were, in fact, well-adjusted (Terman & Oden, 1947). Additionally, Terman’s study showed that the subjects were above average in physical build and attractiveness, dispelling an earlier popular notion that highly intelligent people were “weaklings.” Some people with very high IQs elect to join Mensa, an organization dedicated to identifying, researching, and fostering intelligence. Members must have an IQ score in the top 2% of the population, and they may be required to pass other exams in their application to join the group.
In the past, individuals with IQ scores below 70 and significant adaptive and social functioning delays were diagnosed with mental retardation. When this diagnosis was first named, the title held no social stigma. In time, however, the degrading word “retard” sprang from this diagnostic term. “Retard” was frequently used as a taunt, especially among young people, until the words “mentally retarded” and “retard” became an insult. As such, the DSM-5 now labels this diagnosis as “intellectual disability.” Many states once had a Department of Mental Retardation to serve those diagnosed with such cognitive delays, but most have changed their name to Department of Developmental Disabilities or something similar in language. The Social Security Administration still uses the term “mental retardation” but is considering eliminating it from its programming (Goad, 2013). Earlier in the chapter, we discussed how language affects how we think. Do you think changing the title of this department has any impact on how people regard those with developmental disabilities? Does a different name give people more dignity, and if so, how? Does it change the expectations for those with developmental or cognitive disabilities? Why or why not?
WHY MEASURE INTELLIGENCE?
The value of IQ testing is most evident in educational or clinical settings. Children who seem to be experiencing learning difficulties or severe behavioral problems can be tested to ascertain whether the child’s difficulties can be partly attributed to an IQ score that is significantly different from the mean for her age group. Without IQ testing—or another measure of intelligence—children and adults needing extra support might not be identified effectively. In addition, IQ testing is used in courts to determine whether a defendant has special or extenuating circumstances that preclude him from participating in some way in a trial. People also use IQ testing results to seek disability benefits from the Social Security Administration. While IQ tests have sometimes been used as arguments in support of insidious purposes, such as the eugenics movement (Severson, 2011), the following case study demonstrates the usefulness and benefits of IQ testing.
Candace, a 14-year-old girl experiencing problems at school, was referred for a court-ordered psychological evaluation. She was in regular education classes in ninth grade and was failing every subject. Candace had never been a stellar student but had always been passed to the next grade. Frequently, she would curse at any of her teachers who called on her in class. She also got into fights with other students and occasionally shoplifted. When she arrived for the evaluation, Candace immediately said that she hated everything about school, including the teachers, the rest of the staff, the building, and the homework. Her parents stated that they felt their daughter was picked on, because she was of a different race than the teachers and most of the other students. When asked why she cursed at her teachers, Candace replied, “They only call on me when I don’t know the answer. I don’t want to say, ‘I don’t know’ all of the time and look like an idiot in front of my friends. The teachers embarrass me.” She was given a battery of tests, including an IQ test. Her score on the IQ test was 68. What does Candace’s score say about her ability to excel or even succeed in regular education classes without assistance?
Summary
In this section, we learned about the history of intelligence testing and some of the challenges regarding intelligence testing. Intelligence tests began in earnest with Binet; Wechsler later developed intelligence tests that are still in use today: the WAIS-IV and WISC-V. The Bell curve shows the range of scores that encompass average intelligence as well as standard deviations.
Review Questions
In order for a test to be normed and standardized it must be tested on ________.
- a group of same-age peers
- a representative sample
- children with mental disabilities
- children of average intelligence
B
The mean score for a person with an average IQ is ________.
- 70
- 130
- 85
- 100
D
Who developed the IQ test most widely used today?
- Sir Francis Galton
- Alfred Binet
- Louis Terman
- David Wechsler
D
The DSM-5 now uses ________ as a diagnostic label for what was once referred to as mental retardation.
- autism and developmental disabilities
- lowered intelligence
- intellectual disability
- cognitive disruption
C
Critical Thinking Questions
Why do you think different theorists have defined intelligence in different ways?
Since cognitive processes are complex, ascertaining them in a measurable way is challenging. Researchers have taken different approaches to define intelligence in an attempt to comprehensively describe and measure it.
Compare and contrast the benefits of the Stanford-Binet IQ test and Wechsler’s IQ tests.
The Wechsler-Bellevue IQ test combined a series of subtests that tested verbal and nonverbal skills into a single IQ test in order to get a reliable, descriptive score of intelligence. While the Stanford-Binet test was normed and standardized, it focused more on verbal skills than variations in other cognitive processes.
Personal Application Question
In thinking about the case of Candace described earlier, do you think that Candace benefitted or suffered as a result of consistently being passed on to the next grade?
Glossary
- Flynn effect
- observation that each generation has a significantly higher IQ than the previous generation
- intelligence quotient
- (also, IQ) score on a test designed to measure intelligence
- norming
- administering a test to a large population so data can be collected to reference the normal scores for a population and its groups
- representative sample
- subset of the population that accurately represents the general population
- standard deviation
- measure of variability that describes the difference between a set of scores and their mean
- standardization
- method of testing in which administration, scoring, and interpretation of results are consistent
